Sap Hana
SAP Cloud
SAP HANA Vora
- HANA Vora Hadoop leverages and extends the Apache Spark execution framework to provide enriched interactive analytics on enterprise and Hadoop data
- the HANA Vora Developer Edition cluster is running on top of Hortonworks HDP and Apache Spark
- github: SAP: HANAVora-Extensions Spark extensions for business contexts. SAP has recently contributed a few new features to the Apache Spark ecosystem, available as a GitHub project, including a data hierarchy capability that enables drill-down analysis on Hadoop data, and an extension to Spark’s data source API that improves distributed query efficiency from Spark to SAP HANA.
- github: saphanaacademy: Vora
AMIs
SAP Spark
With over 200,000 customers and among the largest portfolios of enterprise applications, SAP’s software serves as the gateway to one of the most valuable treasure troves of enterprise data globally, and SAP HANA is the cornerstone of SAP’s platform strategy underpinning these enterprise applications moving forward. Now, the community of Spark developers and users will have full access as well, enabling a richness of analytical possibilities that has been hard to achieve otherwise.
- Spark can push down more advanced queries (e.g., complex joins, aggregates, and classification algorithms) – leveraging HANA’s horsepower and reducing expensive shuffles of data
- TGFs (Table Generating Functions) and Custom UDFs (User Defined functions) provide access to the full breadth of Spark’s capabilities through the Smart Data Access functionality
Learn
- SAP HANA Interactive Education hana-shine
Platform
SAP HANA Cloud Platform
- SAP HANA Cloud Platform Trial
- SAP HANA Platform (Core): SAP HANA Development Information - official documentation
Binary Installer
Hardware Requirements
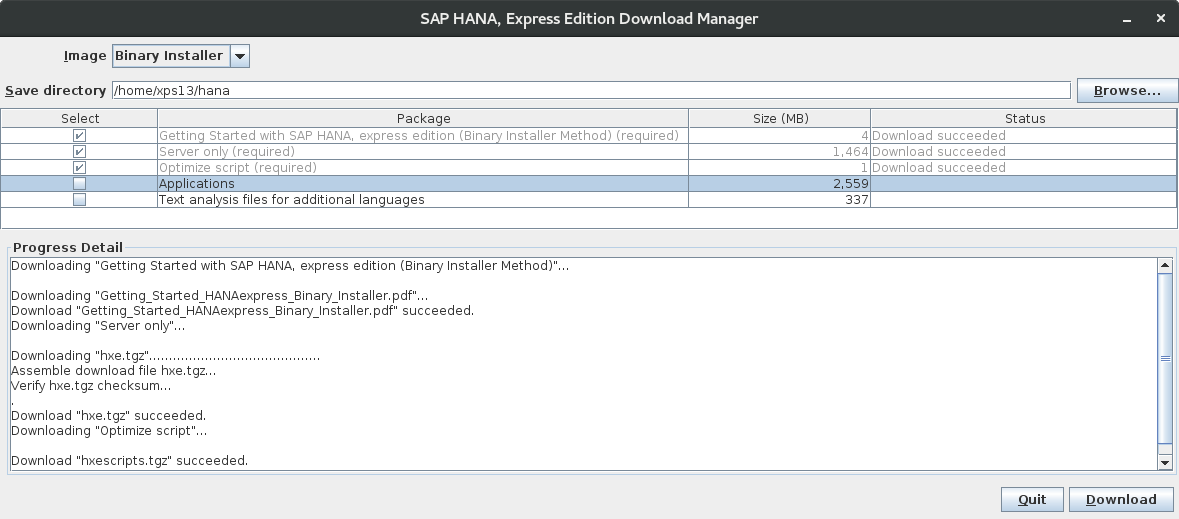
Download Manager
$ chmod +x ~/Downloads/HXEDownloadManager_linux.bin
$ ./HXEDownloadManager_linux.bin
Installation
- Installing Binary: Download the binary image of SAP HANA, express edition, install the image on your Linux server, and install additional tools for express edition if desired.
VM Image
Installation
Usage
- hxehost login
hxeadm- initial password
HXEHana1
Amazon AWS
Functionality
PDF Reference Guides
Predictive Analysis
Sample Algorithms in the Predictive Analysis Library (PAL)
Association Analysis
- Apriori
- Apriori Lite
- FP-growth
- KORD - Top K Rule Discovery
Regression
- Multiple linear regression
- Polynomial regression
- Exponential regression
- Bivariate geometric regression
- Bivariate logarithmic regression
Cluster Analysis
- ABC Classification
- DBSCAN
- K-Means
- K-Medoid Clustering
- K-Medians
- Kohonen self-organizing maps
- Agglomerate hierarchical clustering
- Affinity propagation
Classification Analysis
- CART
- C4.5 decision tree analysis
- CHAID decision tree analysis
- K-nearest neighbor
- Logistic regression
- Back-propagation (neural network)
- Naïve Bayes
- Support vector machine
Time Series Analysis
- Single exponential smoothing
- Double exponential smoothing
- Triple exponential smoothing
- Forecast smoothing
- Autoregressive integrated moving average (ARIMA)
- Brown exponential smoothing
- Croston method
- Forecast accuracy measure
- Linear regression with damped trend and seasonal adjust
Probability Distribution
- Distribution fit
- Cumulative distribution function
- Quantile function
Outlier Detection
- Interquartile range test (Tukey’s test)
- Variance test
- Anomaly detection
Link Prediction
- Common neighbors
- Jaccard coefficient
- Adamic/Adar
- Katzß
Data Preparation
- Sampling
- Random distribution sampling
- Binning
- Scaling
- Partitioning
- Principal component analysis (PCA)
Statistic Functions (Univariate)
- Mean, median, variance, standard deviation
- Kurtosis
- Skewness
Statistic Functions (Multivariate)
- Covariance matrix
- Pearson correlations matrix
- Chi-squared tests:
- Test of quality of fit
- Test of independence
- F-test (variance equality test)
Other
- Weighted scores table
- Substitute missing values