Scala
Parallel Programming
- scala docs: Aleksandar Prokopec, Heather Miller - Parallel Collections Overview
- ibm developerWorks: Dennis Sosnoski - Java and Scala concurrency basics
Lagom Framework
1.3.6
alternatively, use g8 template to start new project
cd ~/src/scala/lagom/lagom-scala-1.4
sbt -Dsbt.version=0.13.15 new https://github.com/lagom/lagom-scala.g8
# start services
sbt runAll
- navigate to localhost:9000/api/hello/World
CURL examples
curl http://localhost:9000/api/hello/Alice
curl -H "Content-Type: application/json" -X POST -d '{"message":"Hi"}' http://localhost:9000/api/hello/Alice
sbt
- create new project
sbt new sbt/scala-seed.g8
sbt can search your local Maven repository if you add it as a repository:
resolvers += "Local Maven Repository" at "file://"+Path.userHome.absolutePath+"/.m2/repository"
or, for convenience:
resolvers += Resolver.mavenLocal
Dependency Management
Coursier
command-line
curl -L -o coursier https://git.io/vgvpD && chmod +x coursier && ./coursier --help
Ammonite
install
mkdir -p ~/.ammonite && curl -L -o ~/.ammonite/predef.sc https://git.io/vH4ju
sudo curl -L -o /usr/local/bin/amm https://git.io/vHz16 && sudo chmod +x /usr/local/bin/amm
amm
ls!
- create script, e.g.
~/Downloads/MyScript.sc - execute script
cd ~/Downloads && amm MyScript.sc
// MyScript.sc
// print banner
println("Hello World!!")
// common imports
import sys.process._
import collection.mutable
// common initialization code
val x = 123
println("x is " + 123)
Notebook
- github: alexarchambault/jupyter-scala
- download from jupyter-scala/releases
- modify
~/.ipython/kernels/scala211/kernel.json
{
"language" : "scala211",
"display_name" : "Scala 2.11",
"argv" : [
"/home/xps13/Downloads/jupyter-scala-0.4.2/jupyter-scala",
"--quiet",
"--connection-file",
"{connection_file}"
]
}
- change file permissions
chmod -R 777 $HOME/.local/share/jupyter
- run
./jupyter-scalainside the directory
Plotting
plotly-scala
- github: alexarchambault/plotly-scala
- github: ASIDataScience/scala-plotly-client
- Web APIs with Scala and Plotly
Mark Lewis
Author of the Introduction to Scala series of books for CS1, CS2 and Data Structures:
- Introduction to the Art of Programming Using Scala (2013)
- Introduction to Programming and Problem Solving Using Scala (2017)
- Object-Orientation, Abstract, and Data Structures Using Scala (2017)
GitHub
- github: MarkCLewis: ProblemSolvingUsingScala
- github: MarkCLewis: OOAbstractDataStructScala => cloned to
ooadsus-book - github: MarkCLewis: OOAbstractDataStructScalaVideos => cloned to
ooadsusandooadsus_gh
YouTube
Links
Docker
EC2 Spot Request
AWS profiles defined at ~/.aws/config. Additional information at aws cli: config-vars and aws cli: request-spot-instances
aws ec2 request-spot-instances --cli-input-json file:///home/xps13/src/scala/observatory/ec2-config.json --profile admin
Contents of ec2-config.json
{
"SpotPrice": "2.064",
"LaunchSpecification": {
"ImageId": "ami-af0fc0c0",
"InstanceType": "c3.8xlarge",
"KeyName": "ami-ca46b6a5-rstudio",
"SecurityGroupIds": [
"sg-91cd7cfa"
]
},
"InstanceCount": 1,
"BlockDurationMinutes": 120
}
- edit security group, add
SSH(port 22) fromMy IPorAnywhere - navigate to folder containing keypair:
$ cd ~/Dropbox/Logins/Amazon/EC2 - remove connection from
/home/xps13/.ssh/known_hosts - connect to instance
ssh -i "ami-ca46b6a5-rstudio.pem" ec2-user@ec2-35-158-91-229.eu-central-1.compute.amazonaws.com
- Installing Docker on Amazon Linux
- The respository cannot be made public for legal reasons. The ec2 main method is available at observatory-ec2.scala
sudo yum update -y # get latest updates
sudo yum install -y docker # install docker (Amazon Linux)
sudo service docker start # start the Docker service
sudo docker pull hseeberger/scala-sbt # install docker image
sudo docker run -it --rm hseeberger/scala-sbt # run image
git clone https://bowerth@gitlab.com/bowerth/observatory.git # clone repo
gpg --passphrase "" observatory/aws-credentials.sh.gpg # decrypt
source observatory/aws-credentials.sh # set S3 credentials
mkdir observatory/src/main/resources # create data folder
wget http://alaska.epfl.ch/files/scala-capstone-data.zip # download data
unzip scala-capstone-data.zip -d observatory/src/main/ # extract data
cd observatory && sbt "run-main observatory.ec2 1975-2015 epfl-observatory stations.csv .csv target/temperatures"
Performace of c3.4xlarge instance running Amazon Linux
- CPU Utilization (max)
77.43%
| Year | Zoom | Time (sec) | Tiles | Time per tile (sec) |
|---|---|---|---|---|
| 1975 | 0 | 22 | 4 | 5.5 |
| 1975 | 1 | 60 | 9 | 6.6 |
| 1975 | 2 | 180 | 25 | 7.2 |
| 1975 | 3 | 600 | 81 | 7.41 |
| Item | Value |
|---|---|
| Tiles per year | 4+9+25+81=119 |
| Years | 2016-1975=41 |
| Total number of tiles | 119*41=4879 |
| Average time per tile (sec) | 7.2 |
| Est. Total time (sec) | 4879*7.2=35128.8 |
| Est. Total time (hrs) | 9.8 |
It is possible to process approx. 10 years in 3 hours.
Packaging
sbt assembly: Standalone jar with all dependencies
If you want to build a standalone executable jar with dependencies, you may use the sbt-assembly plugin (e.g. include in ~/.sbt/0.13/plugins/plugins.sbt). And then build it by
sbt assembly
The standalone will be in target/project_name-assembly-x.y.jar.
You can run it by
java -jar project_name-assembly-x.y.jar [class.with.main.function]
sbt package
create /target/scala-2.11/capstone-observatory_2.11-0.1-SNAPSHOT.jar for distribution
sbt package
Include/exclude files in the resource directory
When sbt traverses unmanagedResourceDirectories for resources, it only includes directories and files that match includeFilter and do not match excludeFilter. includeFilter and excludeFilter have type java.io.FileFilter and sbt provides some useful combinators for constructing a FileFilter. For example, in addition to the default hidden files exclusion, the following also ignores files containing impl in their name,
excludeFilter in unmanagedSources := HiddenFileFilter || "*impl*"
To have different filters for main and test libraries, configure Compile and Test separately:
includeFilter in (Compile, unmanagedSources) := "*.txt"
includeFilter in (Test, unmanagedSources) := "*.html"
Note: By default, sbt includes all files that are not hidden.
jar Commands
- check contents of
.jar jar tvf ./target/scala-2.11/capstone-observatory_2.11-0.1-SNAPSHOT.jar
Amazon Web Services
AWScala
- github: seratch: AWScala Using AWS SDK on the Scala REPL
How to use
libraryDependencies += "com.github.seratch" %% "awscala" % "0.6.+"
Configure credentials in the AWS Java SDK way: docs.aws.amazon.com: credentials
add to ~/.profile:
export AWS_ACCESS_KEY_ID="..."
export AWS_SECRET_ACCESS_KEY="..."
check value of environment variables using sys.env("AWS_ACCESS_KEY_ID")
S3 example
import awscala._, s3._
implicit val s3 = S3.at(Region.Frankfurt)
val buckets: Seq[Bucket] = s3.buckets
// val bucket: Bucket = s3.createBucket("unique-name-xxx")
val bucket = buckets(0)
val summaries: Seq[S3ObjectSummary] = bucket.objectSummaries
// bucket.put("sample.txt", new java.io.File("sample.txt"))
bucket.put("0-0.png", new java.io.File("target/temperatures/1976/0/0-0.png"))
// val s3obj: Option[S3Object] = bucket.getObject("sample.txt")
val s3obj: Option[S3Object] = bucket.getObject("index.html")
val s3url: String = bucket.getObject("index.html").get.publicUrl.toURI.toString
s3obj.foreach { obj =>
val url = obj.publicUrl.toURI.toString // http://unique-name-xxx.s3.amazonaws.com/sample.txt
// obj.generatePresignedUrl(DateTime.now.plusMinutes(10)) // ?Expires=....
// bucket.delete(obj) // or obj.destroy()
println(url)
}
Problem Solving
CafeSat
- github: regb: cafesat: The CafeSat SMT solver for Scala
This is the official repository for the CafeSat source code. CafeSat is a SAT/SMT solver written entirely in Scala. CafeSat attempts provides an efficient command-line tool to solve SMT problems, as well as a library for Scala programs that need the capabilities of SAT/SMT solvers.
Streaming
Tägliche Intervalle reichen aber häufig nicht mehr aus. Gefragt ist Geschwindigkeit: Analysen und Auswertungen werden zeitnah erwartet und nicht Minuten oder gar Stunden später. An dieser Stelle kommt das Stream Processing ins Spiel: Daten werden verarbeitet, sobald sie dem System bekannt sind. Begonnen hat dies mit der Lambda Architektur (vgl. [1]), bei der die Stream- und Batch-Verarbeitung parallel erfolgen, da die Stream-Verarbeitung keine konsistenten Ergebnisse garantieren konnte. Mit den heutigen Systemen ist es auch möglich, nur mit Streaming-Verarbeitung konsistente Ergebnisse nahezu in Echtzeit zu erreichen. (vgl. [2])
Spark
Monix
- monix.io Asynchronous Programming for Scala and Scala.js
Monix is a high-performance Scala / Scala.js library for composing asynchronous and event-based programs, exposing high-level types, such as observable sequences that are exposed as asynchronous streams, expanding on the observer pattern, strongly inspired by ReactiveX and by Scalaz, but designed from the ground up for back-pressure and made to cleanly interact with Scala’s standard library, compatible out-of-the-box with the Reactive Streams protocol.
FS2: Functional Streams for Scala (previously ‘Scalaz-Stream’)
FS2 is a streaming I/O library. The design goals are compositionality, expressiveness, resource safety, and speed. The example below is explained at ReadmeExample.md.
object Converter {
import fs2.{io, text, Task}
import java.nio.file.Paths
def fahrenheitToCelsius(f: Double): Double =
(f - 32.0) * (5.0/9.0)
val converter: Task[Unit] =
io.file.readAll[Task](Paths.get("testdata/fahrenheit.txt"), 4096)
.through(text.utf8Decode)
.through(text.lines)
.filter(s => !s.trim.isEmpty && !s.startsWith("//"))
.map(line => fahrenheitToCelsius(line.toDouble).toString)
.intersperse("\n")
.through(text.utf8Encode)
.through(io.file.writeAll(Paths.get("testdata/celsius.txt")))
.run
// at the end of the universe...
val u: Unit = converter.unsafeRun()
}
// defined object Converter
Converter.converter.unsafeRun()
Handling Resources
Handling data files that are part of a scala project, e.g. for testing functionality.
| /project
|-- /src
|-- -- /main
|-- -- -- /scala/timeusage/TimeUsage.scala
|-- -- -- /resources/timeusage/atussum.csv
|-- /target
|-- -- /scala-2.11
|-- -- /classes
|-- -- -- /timeusage/atussum.csv
The compiler will store /src/main/resources/timeusage/atussum.csv at /target/scala-2.11/classes/timeusage/atussum.csv where it can be found using Paths.get(getClass.getResource("/timeusage/atussum.csv").toURI).toString
Scala API Reference
Continuous Integration
Links
- Scala will be a beginner programming language at LTH
- scala-lang.org Scala
- scala-lang.org Documentation
- scala-lang.org: Getting Started
- scala-lang.org: Scala levels: beginner to expert, application programmer to library designer
- github: scala repo
- website for “Introduction to Programming and Problem Solving Using Scala”
Libraries
better-files
scala-csv
scala-scraper: A Scala library for scraping content from HTML pages
abandon
- select
guiproject $ sbt abandon
> project gui- run with accounts.conf
> run -c /home/xps13/Public/abandon/personal/accounts.conf- assemble jar in
/target/scala-2.11/ > project abandon
> assembly
Testing
ScalaTest
- Install ScalaTest
- save
scalatest_2.11-2.2.6.jarinlibfolder to useimport org.scalatest._
import collection.mutable.Stack
import org.scalatest._
class ExampleSpec extends FlatSpec with Matchers {
"A Stack" should "pop values in last-in-first-out order" in {
val stack = new Stack[Int]
stack.push(1)
stack.push(2)
stack.pop() should be (2)
stack.pop() should be (1)
}
it should "throw NoSuchElementException if an empty stack is popped" in {
val emptyStack = new Stack[Int]
a [NoSuchElementException] should be thrownBy {
emptyStack.pop()
}
}
}
ScalaCheck
If you use sbt add the following dependency to your build file
libraryDependencies += "org.scalacheck" %% "scalacheck" % "1.13.0" % "test"
Put your ScalaCheck properties in src/test/scala, then use the test task to check them
$ sbt test
+ String.startsWith: OK, passed 100 tests.
! String.concat: Falsified after 0 passed tests.
> ARG_0: ""
> ARG_1: ""
+ String.substring: OK, passed 100 tests.
Specify some of the methods of java.lang.String like this:
import org.scalacheck.Properties
import org.scalacheck.Prop.forAll
object StringSpecification extends Properties("String") {
property("startsWith") = forAll { (a: String, b: String) =>
(a+b).startsWith(a)
}
property("concatenate") = forAll { (a: String, b: String) =>
(a+b).length > a.length && (a+b).length > b.length
}
property("substring") = forAll { (a: String, b: String, c: String) =>
(a+b+c).substring(a.length, a.length+b.length) == b
}
}
Concepts
XML
- github: databricks: spark-xml
- github: elsevierlabs-os: spark-xml-utils
- hars.de: Processing real world HTML as if it were XML in scala
- alvinalexander.com: Parsing ‘real world’ HTML with Scala and HTMLCleaner
Stack size
- run jar with increased JVM stack size
$ scala -J-Xss200m LoopTesterApp
Tail Recursion
Implementation Consideration
If a function calls itself as its last action, the function’s stack frame can be reused. This is called tail recursion. Tail recursive functions are iterative processes.
In general, if the last action of a function consists of calling a function (which may be the same), one stack frame would be
sufficient for both functions. Such calls are called tail-calls.
Tail Recursion in Scala
In Scala, only directly recursive calls to the current function are optimized. One can require that a function is tail-recursive using a @tailrec annotation:
@tailrec
def gcd(a: Int, b: Int): Int = ...
If the annotation is given, and the implementation of gcd were not tail recursive, an error would be issued.
Usage
IDEs
Sublime
- run on
.scalafile Ctrl + Shift + PthenShow Scala Worksheet(bound toAlt + W)
Web Frameworks
Spring
Scalatra
Scalatra is a simple, accessible and free web micro-framework. It combines the power of the JVM with the beauty and brevity of Scala, helping you quickly build high-performance web sites and APIs.
Android
- code.google.com: scalaforandroid
- macroid.github.io: ScalaOnAndroid
- github.com: saturday06: gradle-android-scala-plugin
- github: pocorall: scaloid
Macroid
- install dependencies
$ android sdk updateand select in category “Extras”Android Support RepositoryandGoogle Repository
Advantages
- scalability: seamless operability with Java: call Java methods, access Java fields, inherit from Java classes, and implement Java interfaces
- compatibility
- brevity
- high-level abstractions
- advanced static typing: static type system classifies variables and expressions according to the kinds of values they hold and compute
- functional: more elegant programs, parallel, concurrent,
- functions can be defined anywhere, including inside other functions; functions are like any other value, they can be passed as parameters to functions and returned as results; as for other values, there exists a set operators to compose functions
In Java, you say everything three times, in Scala you say everything one time. Closures (function values) arrived in Java 8 - in Scala existing from the beginning.
val people: Array[Persons]
val (minors, adults) = people partition (_.age < 18)
to make it parallel: val (minors, adults) = people.par partition (_.age < 18) (collection)
Akka framework
- akka.io
- Scala Documentation
- Akka API ScalaDoc
- The Neophyte’s Guide to Scala Part 8: Welcome to the Future
Akka Streams
- Akka Documentation: Streams
- baeldung: Guide to Akka Streams
- zalando: About Akka Streams
- slideshare: Streaming all the things with akka streams
Akka-HTTP
Typesafe Activator
Slick for database access
- slick.typesafe.com Functional Relational Mapping for Scala
- typesafe: hello-slick 3.0
- H2 Database
- playframework: documentation: H2 database
Play Slick Module
Tutorials
- typesafe: play-slick (2014)
- typesafe: play-slick-quickstart
- github: loicdescotte: activator-play-slick
- modify
conf/application.confto use a file-based database db.default.url="jdbc:h2:/path/to/filee.g.jdbc:h2:data/testwill generate/data/test.h2.dbin application root
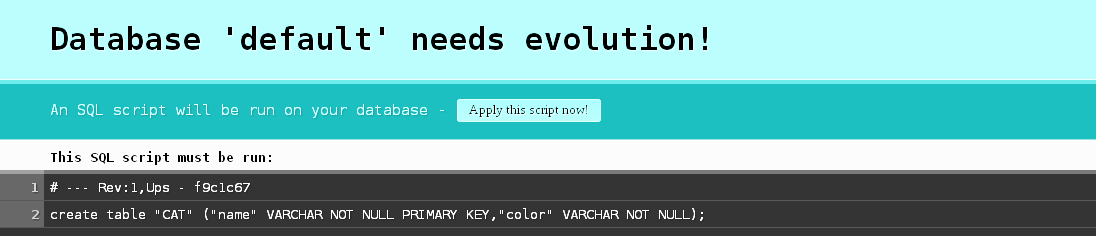
- browse file-based database using activator (starting Web Console server at
http://192.168.1.38:8082) $ activator->h2-browser

- edit table simultaneously from h2-browser Web Server console and play application running at
localhost:9000 - query table
SELECT * FROM CAT name
edit table@edit SELECT * FROM CAT name
Play Framework
- reactivemanifesto.org Responsive, Resilient, Elastic and Message Driven Systems
- Play framework
- Play Scala documentation
- github: playframework: playframework
- Build from source
- Download link offline version typesafe-activator-1.3.7.zip (477M / 502M)
- Download link minimal version typesafe-activator-1.3.7-minimal.zip (1M)
- creating an application
$ activator new- starting an application
$ cd play-scalajs-showcase
$ activator run- launch activator desktop
$ activator ui
Play libraries
Deployment General
jQuery
- knoldus.com: Integrate Jquery DataTable with Scala Play Framework
- github: abdheshkumar: PlayFrameWork_DataTable
- stackoverflow: internationalize datatable columns specification
mongoDB
Templates
Activator template for a Play, MongoDB and knockout.js application
Starting with ReactJS, Play 2.4.x, Scala and Anorm
Reactive-Maps
Geographic data processing
ARG
- geotrellis.io: rasterlayers
- github: geotrellis: ArgFileRasterLayer.scala
- github: geotrellis: ArgWriter
GeoTrellis
- github: geotrellis: geotrellis
- github: GeoTrellis Spark
- geotrellis.github.io: scaladocs: geotrellis.package
GeoTrellis Transit
GeoTrellis Chattanooga Model Demo
Spray-based web application that uses GeoTrellis to do a weighted overlay and zonal summary over land raster data for a project that was completed for the University of Chattanooga at Tennessee
- usage
$ cd ~/scala/geotrellis/geotrellis-chatta-demo/geotrellis
$ sbt run
Tutorial
- geotrellis.io: spray webservice tutorial
- [github: geotrellis: geotrellis-spray-tutorial]https://github.com/geotrellis/geotrellis-spray-tutorial)
- change port in
src/main/scala/Main.scala IO(Http) ! Http.Bind(service, interface = "localhost", port = 9000)- start application
$ cd ~/scala/geotrellis/geotrellis-spray-tutorial
$ sbt
$ run
demo REST queries in src/main/scala/GeoTrellisService.scala
-
http://localhost:9000/ping
-
http://localhost:9000/raster/SBN_inc_percap/draw
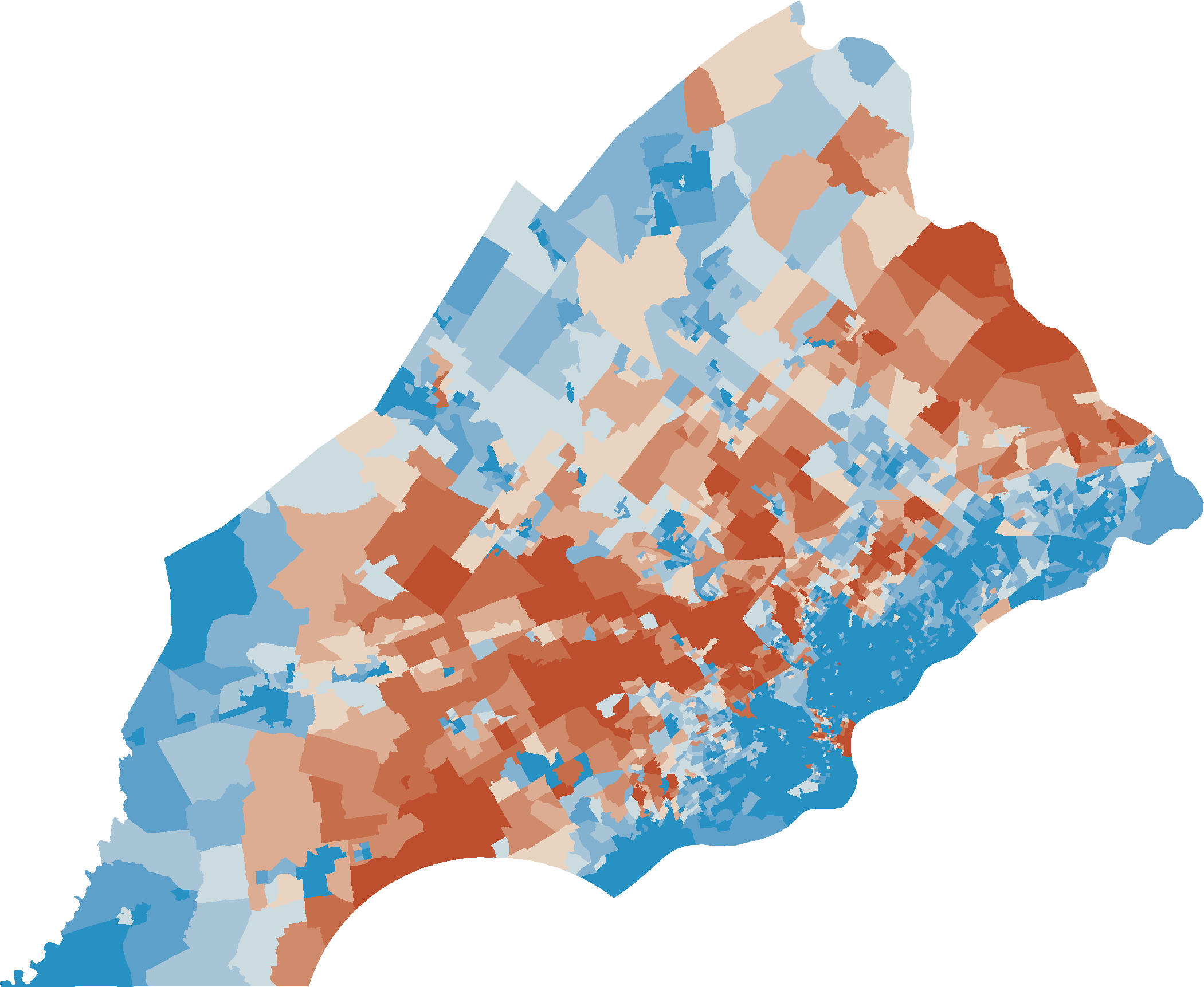
- http://localhost:9000/raster/SBN_inc_percap/stats
{mean: 26.62950322073986, histogram: [[2,34170],[4,43733],[6,17490],[8,47435],[10,53341],[12,122251],[14,82596],[16,96651],[18,183408],[20,95711],[22,98655],[24,89779],[26,78115],[28,101714],[30,102065],[32,41440],[34,72890],[36,42396],[38,33185],[40,11975],[42,26356],[44,36012],[46,18198],[48,20421],[50,28087],[52,27513],[54,6932],[56,9250],[58,17249],[60,6554],[62,17552],[64,19696],[66,1598],[68,3993],[70,8216],[72,2563],[76,13021],[78,2813],[80,550],[82,7726],[86,3025],[88,317],[92,2843],[94,1385],[96,2860],[98,556],[100,2582]] }
- http://localhost:9000/raster/SBN_farm_mkt/draw
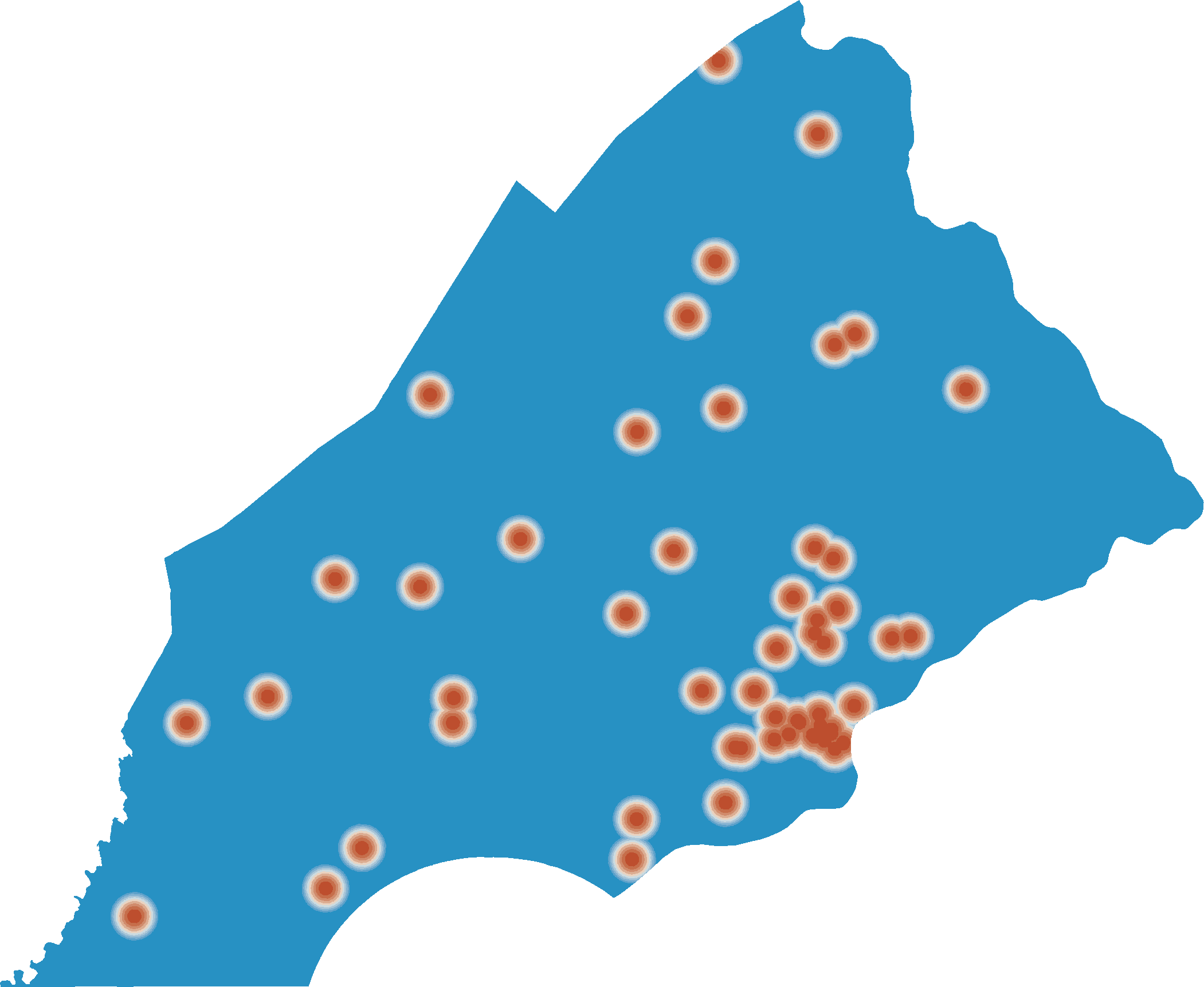
- http://localhost:9000/raster/SBN_farm_mkt/mask?cutoff=1
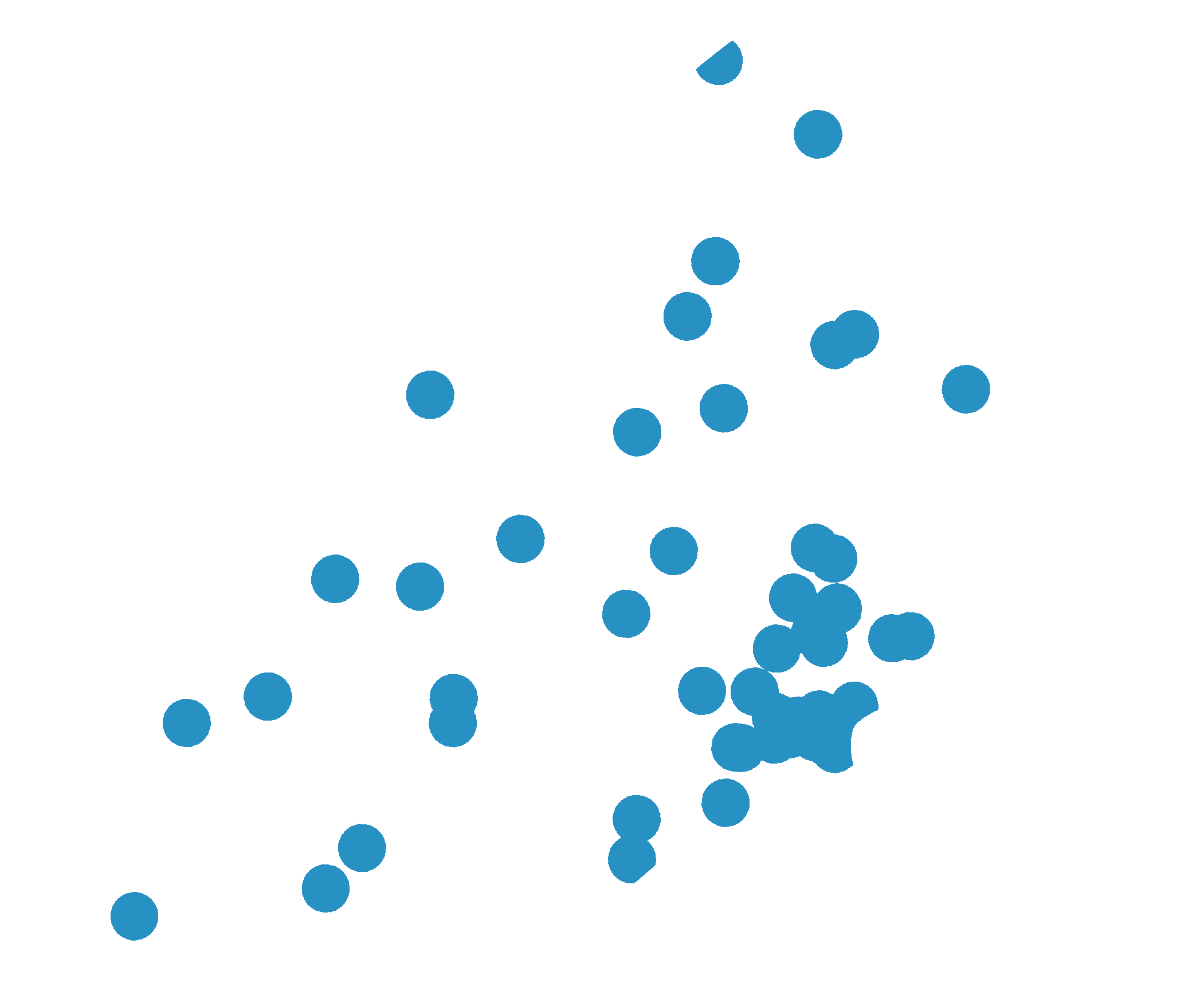
- http://localhost:9000/analyze/draw?cutoff=1
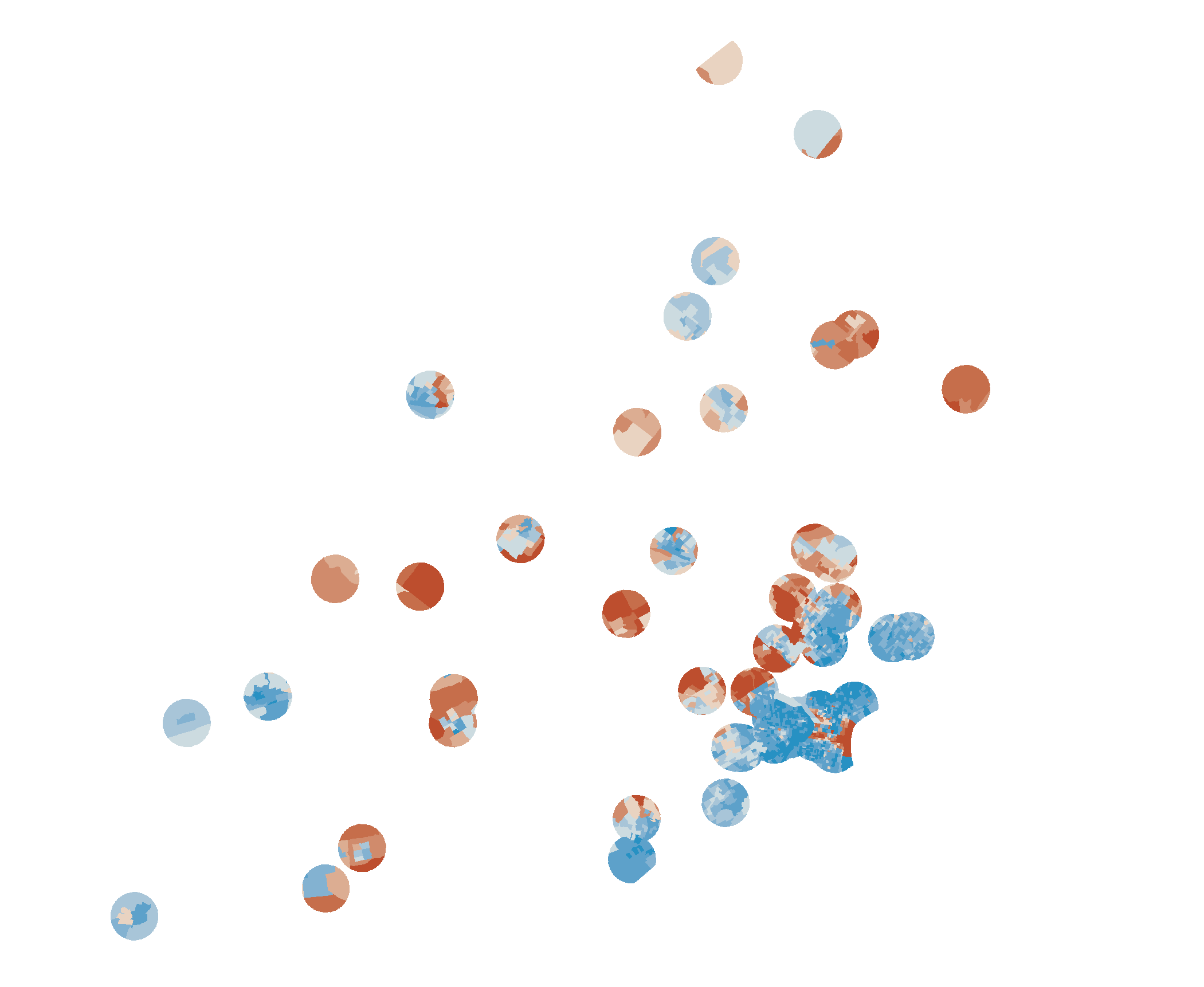
- http://localhost:9000/analyze/stats?cutoff=1
{mean: 22.955766888898363, histogram: [[2,10576],[4,22930],[6,7207],[8,8310],[10,10010],[12,13177],[14,12758],[16,9399],[18,18027],[20,4039],[22,5779],[24,9623],[26,4040],[28,10650],[30,9280],[32,5161],[34,6067],[36,3497],[38,4232],[40,1171],[42,6380],[44,5903],[46,2785],[48,1917],[50,1504],[52,5465],[54,892],[56,468],[58,1336],[60,1220],[62,803],[64,1342],[66,467],[68,620],[70,956],[72,135],[76,373],[78,57],[80,59],[82,140],[86,22],[88,31],[92,1095],[96,223],[100,915]] }
Scalaz
An extension to the core Scala library for functional programming.
It provides purely functional data structures to complement those from the Scala standard library. It defines a set of foundational type classes (e.g. Functor, Monad) and corresponding instances for a large number of data structures.
Resources
Let the types speak for themselves via the Scalaz Scaladocs!
The examples module contains some snippets of Scalaz usage.
The wiki contains release and migration information.
The typelevel blog has some great posts such as Towards Scalaz by Adelbert Chang.
Learning Scalaz is a great series of blog posts by Eugene Yokota. Thanks, Eugene!
Scala.js
- www.scala-js.org
- github.com: scala-js: scala-js
- lihaoyi.github.io: hands-on-scala-js
- scala.js Fiddle
- underscore.io: Towards Browser and Server Utopia with Scala.js
- github: Karasiq: scalajs-highcharts
- to run code with Node.js (instead of Rhino)
$ sbt
> set scalaJSStage in Global := FastOptStage
> last- get stack traces resolved on Node.js
$ npm install source-map-support- create single JavaScript file from sbt
> fastOptJSor recompile as needed> ~fastOptJS- after changes to
build.sbtreload the sbt configuration - Hit enter to abort the
~fastOptJScommand
Typereload
Start~fastOptJSagain - enable testing with uTest (depends on phantomJS)
- install phantomJS
$ npm install -g phantomjs
$ sbt
> run
|.
|
|- project/
|
|-- build.sbt
|
|-- src
|
|--- main
|
|---- scala
|
|----- program.scala
|
|--- test
|
|---- scala
|
|----- test.scala
D3
React
Scala.js Single Page Application (SPA)
Scala.js Tutorial
wootjs
WOOT model for Scala and JavaScript via Scala.js
- usage
$ cd ~/scala/wootjs
$ sbt "project server" runor$ sbt server/run
SBT
Use Scala to define your tasks. Then run them in parallel from the shell.
Customizing paths
- unmanaged source directories
scalaSourceandjavaSource
Organizing Build
project/Dependencies.scalato track dependencies in one place
Cross-build projects
Multi-build projects
- list projects from
sbt > projects- select specific project
> project [project name]
Project structure
|.
|
|- project/
|
|-- build.sbt
|
|-- program.scala
build.sbt- make sure scala version is the same as installed (version printed when running
$ scalafrom Linux shell)
giter8
- install conscript
$ curl https://raw.githubusercontent.com/n8han/conscript/master/setup.sh | sh- install giter8 templating system
$ cs n8han/giter8- fetch template
- execute in new project folder
$ g8 typesafehub/scala-sbt
- ensime template github: tnoda: sbt-ensime.g8
- Scala project with release configuration, cross-builds and stuff lunaryorn/scala-seed.g8
ENSIME
create project/EnsimeProjectSettings.scala
import sbt._
import org.ensime.Imports.EnsimeKeys
object EnsimeProjectSettings extends AutoPlugin {
override def requires = org.ensime.EnsimePlugin
override def trigger = allRequirements
override def projectSettings = Seq(
// your settings here
)
}
- run sbt
$ sbtor from EmacsM-x sbt-start - compile project
> compile - generate
.ensimefor the project - generate
project/.ensimefor the project definition - add
.ensime,project/.ensimeandproject/EnsimeProjectSettings.scalato.gitignore
SBT Commands
The commands become available after adding ensime to the global SBT plugins (Windows: C:\Users\[username]\.sbt\0.13\plugins.sbt, Linux: ~/.sbt/0.13/plugins.sbt)
- Generate a .ensime for the project (takes space-separated parameters to restrict to subprojects)
ensimeConfig(previouslygen-ensime)- Generate a project/.ensime for the project definition.
ensimeConfigProject(previouslygen-ensime-project)- Add debugging flags to all forked JVM processes.
> debugging- Remove debugging flags from all forked JVM processes.
> debugging-off
Examples
Spark
MLlib
We show a simple Scala code example for ML dataset import/export and simple operations. More complete dataset examples in Scala and Python can be found under the examples/ folder of the Spark repository. We refer users to Spark SQL’s user guide to learn more about SchemaRDD and the operations it supports.
Events
Videos
2016 Video Replays
Learn
- The Guardian: pairing tests
- blog.codacy.com: How to learn Scala
- Heather Miller: Distributed Data-Parallel Programming
Creative Scala
- setup
$ cd ~/Dropbox/GitHub/creative-scala
$ npm install- usage
$ grunt watchand navigate tohttp://localhost:4000
Books
- Scala for data science, Pascal Bugnion PACKT Publishing
- github: pbugnion: s4ds
- Programming in Scala: A Comprehensive Step-by-Step Guide, 2nd Edition, by Martin Odersky, Lex Spoon, and Bill Venners Artima Press, HTLM version
- github: elephantscale: learning-scala
- Scala for the Impatient
- Joshua D. Suereth - Scala in Depth
- Dean Wampler, Alex Payne - Programming Scala
Coursera
Functional Programming Principles in Scala
by Martin Odersky, École Polytechnique Fédérale de Lausanne
Principles of Reactive Programming
by Martin Odersky, Erik Meijer, Roland Kuhn, École Polytechnique Fédérale de Lausanne
Installation Windows
- set
JAVA_HOME - create
.batscript
set SCRIPT_DIR=%~dp0
rem java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M -jar "%SCRIPT_DIR%sbt-launch.jar" %*
%JAVA_HOME%\bin\java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M -jar "%SCRIPT_DIR%sbt-launch.jar" %*
Installation Fedora 22
- install
sbt curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
sudo dnf install sbt
this will create a link in /usr/bin/sbt
in order to call sbt from the command line, add the following to ~/.profile:
export SCALA_HOME="/usr/share/scala"
export SBT_HOME="/usr/share/sbt-launcher-packaging"
export PATH="$PATH:$SBT_HOME/bin:$SCALA_HOME/bin
Usage
- go to test project folder
cd /home/xps13/Dropbox/Programming/Scala/hello2
create hw.scala if it doesn’t exist already
object Hi {
def main(args: Array[String]) {
println("Hi!")
}
}
- generate directory for classes
mkdir classes- generate class files in output directory (classpath)
scalac -d classes hw.scala- execute bytecode with classpath
scala -cp classes HireturnsHi!
generate shell script hw_script.sh
#!/bin/sh
exec scala "$0" "$@"
!#
object Hi extends App {
println("Hi!")
}
Hi.main(args)
- make executable and run
chmod +x hw_script.sh
./hw_script.sh
Debugging
- if
sbtcannot find all dependencies, checkbuild.propertiesfiles inprojectsubfolders forsbt.version=0.13.xand update with installedsbtversion - installed
sbtversion can be checked by runningsbt sbtVersionfrom within a non-project directory
Compiling
- navigate to directory
$ cd ~/Dropbox/Programming/Scala/prog-in-scala/ch4/- compile source code to class files
$ scalac ChecksumAccumulator.scala Summer.scala- using Scala compiler daemon called
fsc $ fsc ChecksumAccumulator.scala Summer.scala- stop the fsc daemon
$ fsc -shutdown
Conferences
- Scala Days
- BeeScala
- Scala.io
- w-jax Die Konferenz für Java, Architektur- und Software-Innovation
- topconf
- Scala Italy